Full Text Search using Apache Lucene (Part-II)
In this post, I shall discuss about what is a Lucene Index, how to index and anlayse data. This is in continuation to my earlier post Full Text Search using Apache Lucene (Part-I)
Indexing Data
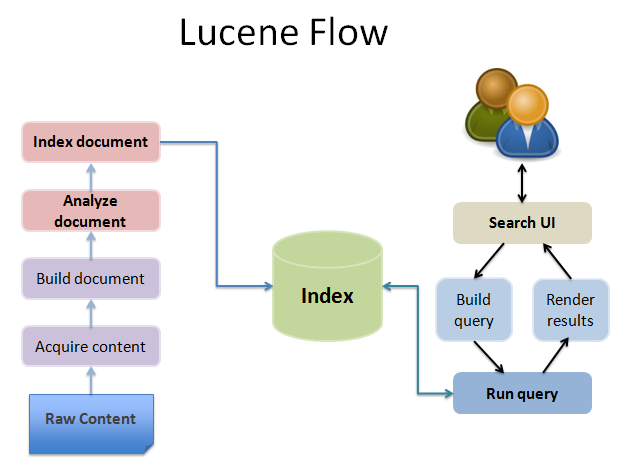
The first step in building a search application using Lucene is to index data that needs to be searched. Any data available in textual format can be indexed using Lucene. Lucene can also be used with any data source as long as textual information is extracted from it.
Indexing is the process of converting textual data into a format that facilitates rapid searching. Simple example is an index at the end of a book, which points reader to the page of the topic that appear in the book. Lucene stores the input data in a data structure called an inverted index, which is stored on the file system or memory as a set of index files. It lets users to perform fast keyword look ups.
Following code snippets shows configuration of index in a file system.
<prop key=”hibernate.search.default.directory_provider”>filesystem</prop>
<prop key=”hibernate.search.default.indexBase”>/var/gracular/index</prop>
The below annotation tells the hibernate application to create a Lucene index for database table patents
@Entity
@Indexed(index=”patent”)
@Table(name=”patents”,catalog=”gracular_2″)
Indexing of data internally involves various steps.
- Analysis:
Analysis is converting the text data into a fundamental unit of searching, which is called as term. During analysis, the text data goes through multiple operations: extracting the words, removing common words, ignoring punctuation, reducing words to root form, changing words to lowercase, etc. Analysis happens just before indexing and query parsing. Analysis converts text data into tokens, and these tokens are added as terms in the Lucene index.
Lucene comes with various built-in analyzers, such as SimpleAnalyzer, StandardAnalyzer, StopAnalyzer, SnowballAnalyzer, and more. These differ in the way they tokenize the text and apply filters. As analysis removes words before indexing, it decreases index size, but it can have a negative effect on precision query processing. In addition to existing analyzers, users can define their custom analyzers.
Below code snippets creates a custom analyzer which tokenize terms based on delimeter ‘,’
@AnalyzerDef(
name=”customanalyzer”,
tokenizer=@TokenizerDef(factory=PatternTokenizerFactory.class,params=
@Parameter(name=”pattern”,value=”,”))
)
- Adding data to Index
There are two classes involved in adding text data to the index: Field and Document. Field represents a piece of data queried or retrieved in a search. The Field class encapsulates a field name and its value. Lucene provides options to specify if a field needs to be indexed or analyzed and if its value needs to be stored.
Document is a collection of fields. Lucene also supports boosting documents and fields, which is a useful feature if you want to give importance to some of the indexed data. Indexing a text file involves wrapping the text data in fields, creating a document, populating it with fields, and adding the document to the index using IndexWriter.
Below code snippet adds patent name column data to index and boosts its relevance value by 5 times.
@Column(name=”patent_name”,nullable=false,length=200)
@Index(name=”patentName”)
@Fields({
@Field,
@Field(name=”patentName”, analyze=Analyze.NO)
})
@Boost(value=5f)
private String patentName;
I shall discuss about how to search Indexed data in my next post.
